Cooperative Listening Devices
This post describes our paper “Cooperative Audio Source Separation and Enhancement Using Distributed Microphone Arrays and Wearable Devices,” presented at CAMSAP 2019.
Introduction
Imagine what it would sound like to listen through someone else’s ears. I don’t mean that in a metaphorical sense. What if you had a headset that would let you listen through microphones in the ears of someone else in the room, so that you can hear what they hear? Better yet, what if your headset was connected to the ears of everyone else in the room? In our group’s latest paper, “Cooperative Audio Source Separation and Enhancement Using Distributed Microphone Arrays and Wearable Devices,” presented this week at CAMSAP 2019, we designed a system to do just that.
Our team is trying to improve the performance of hearing aids and other augmented listening devices in crowded, noisy environments. In spaces like restaurants and bars where there are many people talking at once, it can be difficult for even normal-hearing people to hold a conversation. Microphone arrays can help by spatially separating sounds, so that each user can hear what they want to hear and turn off the sounds they don’t want to hear. To do that in a very noisy room, however, we need a large number of microphones that cover a large area.
Distributed array

In the past, we’ve built large wearable microphone arrays with sensors that cover wearable accessories or even the entire body. These arrays can perform much better than conventional earpieces, but they aren’t enough in the most challenging environments. In a large, reverberant room packed with noisy people, we need microphones spread all over the room. Instead of having a compact microphone array surrounded by sound sources, we should have microphones spread around and among the sound sources, helping each listener to distinguish even faraway sounds.
Fortunately, we are already surrounded by microphones. Most people carry mobile devices with at least two microphones, and many have wearable accessories like smart watches, glasses, and headphones that also contain microphones. (Better yet, they could wear some of the fashionable microphone-array accessories that our team is designing!) Televisions, telephones, computers, game consoles, conferencing equipment, security cameras, and voice-assistant speakers add even more available microphones. If all those microphones could be connected together into one giant array, we could give people superhuman hearing even in the noisiest situations.
Of course, it’s not as simple as just connecting all the devices in a room together. Even if all the devices were designed to work together with a uniform standard, they must communicate over a network that has limited bandwidth and possibly significant delays. Furthermore, in a wireless system, each device has its own clock crystal that tells it when to collect audio samples. One device might sample at 16,001 Hz and one might sample at 15,999 Hz. It is possible to correct for these offsets, but it can be difficult and time-consuming, especially if people are walking around the room.
Cooperative architecture
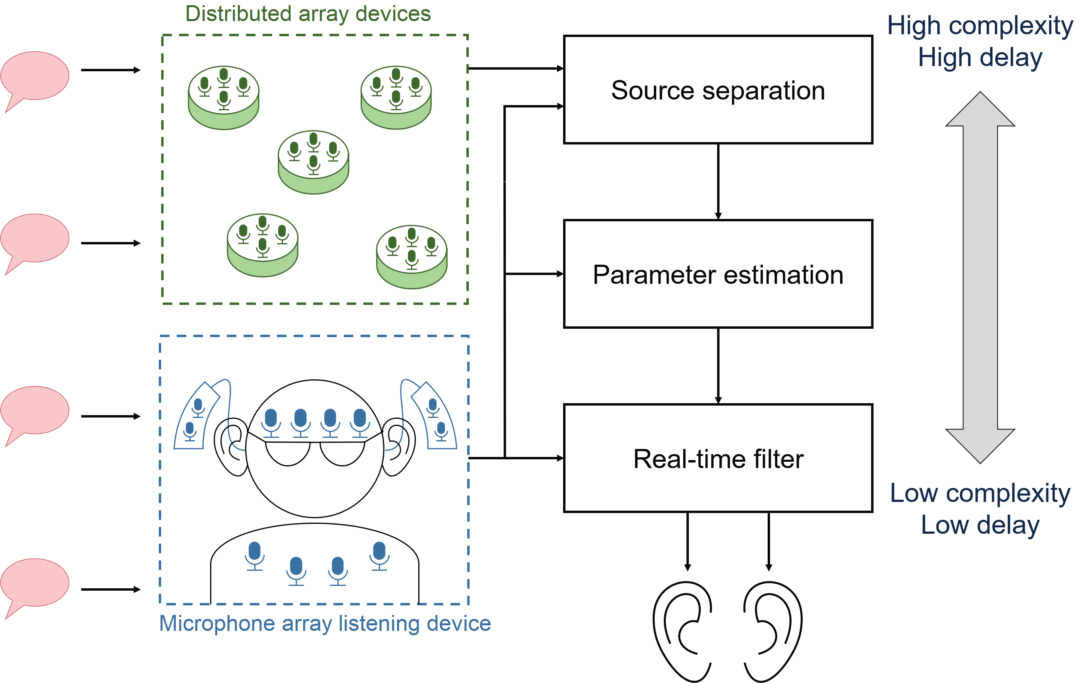
In this paper, we propose a cooperative processing system that takes advantage of the strengths of each type of device. Wearable devices are valuable because they are as close as we can get to people who are talking, but they are also challenging to use because they tend to move frequently and have severe size and power constraints. Microphones in appliances such as smart speakers are easy to use because they rarely move, can be more easily synchronized across a network, and can typically use more computational power compared to wearables. In the future, rooms that regularly host large noisy groups might be deliberately covered in microphones; such infrastructural microphones would be especially valuable because we know in advance where they are.
But a user’s listening device might not be able to use these remote microphones directly for beamforming: it would take too long to transmit the data over a wireless network. Listening devices need to process sound within a few milliseconds to avoid a disturbing echo. Processing data from the full array would also require a lot of bandwidth and computational power that would be difficult for a wearable.
Our proposed cooperative system divides signal processing tasks into different scales of time and distance. All the microphones in the room are used for difficult tasks like blind source separation, which takes a long time and uses a lot of data. The source separation system, which would run on a powerful computer or the cloud, decides what sources are in the room, where they are, and how sound propagates from the sources to each user’s listening device. Then, each listening device uses this information to design its own beamformer that uses only its own nearby microphones. That is, your hearing aid works with other hearing aids and microphones in the room to learn about the acoustics of the room and the properties of the sounds, then works by itself to produce the sound that you hear.
Experiment

To show how a cooperative listening system would work, Ryan Corey and Matt Skarha filled a conference room with 160 microphones. There were 16 microphones on each of 4 mannequin “listeners,” who had behind-the-ear earpieces, microphone-equipped glasses, and microphone-covered shirts. To simulate microphone-equipped devices in the room, we used 12 smart-speaker enclosures, designed by Uriah Jones and Ben Stoehr, with 8 microphones each. These were placed on tables throughout the room. To simulate a noisy party, we set up 10 loudspeakers at roughly head height on stands. They played back frequency sweeps used to measure room acoustics and speech samples from the VCTK data set. This massive array data set is freely available on the Illinois Data Bank.
We used all 160 microphones to do semi-blind source separation using an algorithm called independent vector analysis (IVA). It was semi-blind instead of fully blind because we told the algorithm how many loudspeakers there were and which recording device was closest to each loudspeaker. From the results of that algorithm, we calculated how each sound source propagated acoustically to each microphone of the wearable arrays. Each wearable array used its 16 microphones to beamform separately onto each source. Because these are listening devices, the beamformers were designed to have imperceptibly short delay and to preserve the spatial cues of the sources. That is, a sound source that’s across the room and to the right should still sound like it’s across the room and to the right, and a sound source that’s nearby and to the left should sound like it’s nearby and to the left in the processed output.
You can watch the video above for some examples. You’re listening through the two ears of a mannequin, so wear earbuds to evaluate the spatial cues in the room. As you might expect, the system worked best for listeners and talkers that are close together. It doesn’t work as well for faraway talkers, but it’s still better than a single device could do on its own. Our demos page has speech clips for every source-listener pair and several source separation methods.
We found that the cooperative listening system was limited by the source separation algorithm. The listening device designs its beamformer to focus on whatever the source separation algorithm tells it to. In the future, we’ll work on improved source separation algorithms that can take advantage of large numbers of microphones to better deal with noise and reverberation. We also need to improve the system to deal with movement and synchronization, which we’ve addressed in previous papers.
After this technology is developed, you might be able to walk into a big, crowded room and use hundreds of microphones to help you hear perfectly over the din.